반응형
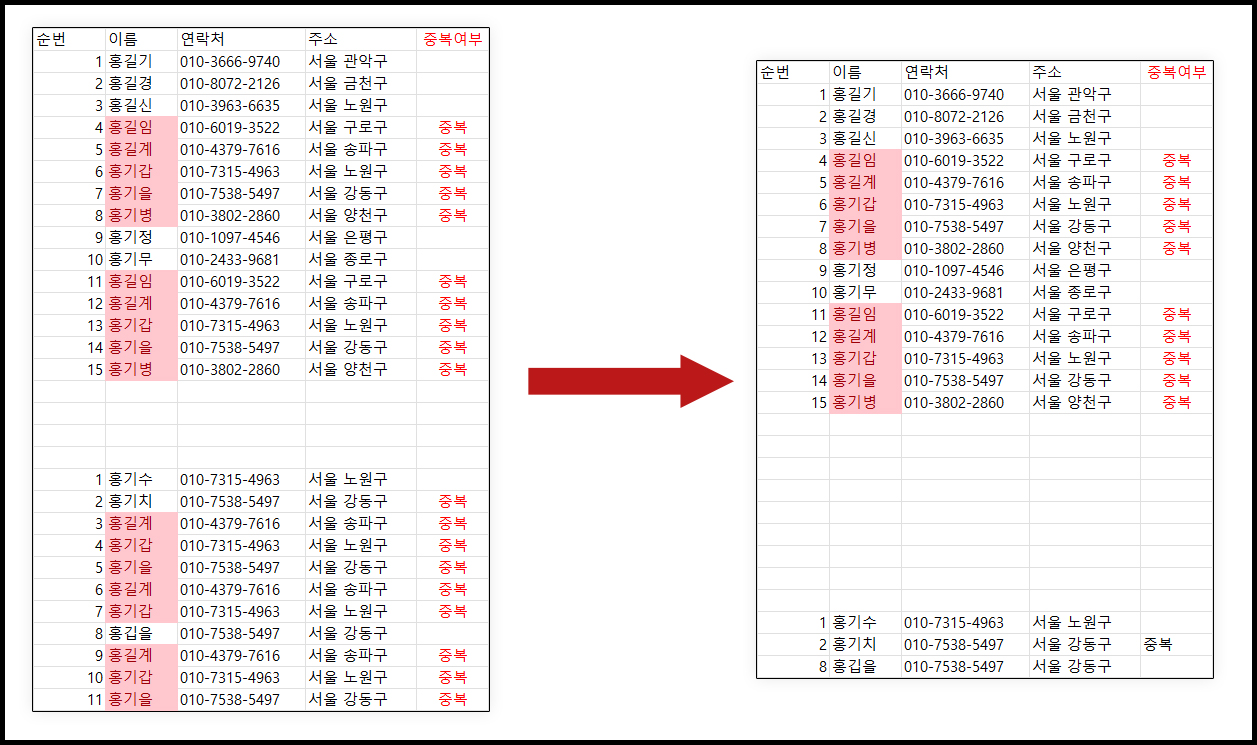
엑셀로 DB를 다루다보면 기존의 DB는 유지 한 채 새로운 DB와 비교하여 중복되는 DB만을 제거 하고 싶을 때가 있습니다.
엑셀의 기본 기능인 ‘중복 제거’를 이용할 경우 기존 DB까지 모두 중복 제거 되는 등, 기존 DB의 변경이 일어날 수 있기 때문에 파이썬을 이용해서 간단하게 새로운 DB 한해서 중복 제거 하는 프로그램을 만들어 보겠습니다.
시작하기 전,
이번 포스팅에서는 win32com(설치 필요), itertools, re 세가지 라이브러리를 사용할 예정입니다.
win32com가 설치 되어 있지 않은 분은 아래 명령어를 통해 라이브러리를 설치해 주시기 바랍니다.
pip install pywin32
코드 재활용을 위해 클래스 함수를 이용하여 코딩을 진행하겠습니다.

- (1~2행)우선 클래스를 정의하고 초기화를 진행합니다.
- (3행)엑셀을 디스패치하여 excel에 담아줍니다.
- (4행)진행 과정을 확인하기 위하여 excel.Visible 값을 True로 지정
- Visible 함수는 엑셀 파일을 열어 프로그램을 창을 뛰우는 역할을 하는 함수입니다. 엑셀 프로그램을 실행하지 않고 작업하고 싶다면 False 값을 주시면 됩니다.
- (5행)현재 열려 있는 엑셀의 sheet를 로드하기 위해 excel.activesheet 함수를 쓰도록 하겠습니다.
- 만약 파일을 열어서 하고 싶다면 Workbooks.Open(”파일경로”)를 이용하여 주시기 바랍니다.
- (2행)다음으로 파라미터 3개를 갖는 클래스내 함수 만들어 주도록 할텐데, 각각 기존의 DB 있는 범위를 선택하기 위한 “old”변수, 새로운 DB범위를 선택하기 위한 “new” 변수, 그리고 중복값을 비교할 열 이름 “search_col” 를 넣어 주도록 하겠습니다.
- (3행) 그 중 새로운 범위를 “new” 변수는 다른 클래스 함수에서 사용할 예정이기 때문에 지역 변수의 값으로 할당하여 줍니다.
- (5행)기존의 DB 값들을 가줘와야 하는데, 범위를 지정하는 방법도 있지만, 여기서는 변수의 셀 주소를 기준으로 “인접한” 곳에 데이터가 있으면 모두 불러오는 방법을 사용할 예정입니다.
- (5행)현재 시트(self.sht)에서 기준이되는 셀(Range(old))의 인접한 셀들(currentregion)의 값(value)를 불러와 curnt_db에 담고
- (6행)curn_db를 2차원 배열에서 1차원 배열로 전환(itertools.chain 함수 사용) 하여 리스트로 변경 후 클래스 지역변수(self.curnt_db)에 담아 줍니다.
- (7~8행) 코드를 한 줄로 작성할 수도 있지만, 가독성을 위해 두줄로 나눠서 작성해주었습니다.
- (7행) 7번과 같은 방식으로 새로운 DB의 값도 클래스 지역변수로 만들어 담아 줍니다.
- (9~15행) 데이터 출력을 위해 엑셀 형식의 셀주소(a1,a3 등)같은 주소방식을 열번호, 행번호([1,1]나 [2,5] 같은)로 변환하는 코드를 작성해줍니다.
- (9행) 문자만 찾는 정규식 코드
- (10행) 숫자만 찾는 정규식 코드
- (12행) 셀주소에서 문자만을 찾아 아스키 코드로 변환(ord())하고 엑셀 첫 열이름인 a를 기준으로 빼고 +1를 해줍니다. a열의 값은 1, b열의 값은 2가 나옵니다.
- re.findall()함수는 배열 값을 출력하는데, 셀주소를 통해 찾고자 하는 정규식에 해당하는 내용은 하나 밖에 없을 예정이므로 [0]을 입력했습니다.
- lower() 함수를 이용해 셀주소에 대문자를 입력해서 나올 수 있는 오류를 방지해줍니다.

- (2행) 이제 중복되지 않은 값을 찾고, 데이터를 입력하는 할 수 있는 클래스 내 함수를 하나 만들어 주도록 하겠습니다.
- (3행) 중복되지 않은 데이터를 저장할 빈 리스트(new_list)를 하나 만들어주시고
- (4~6행) 새로운 디비를 행단위로 빼내어 position 함수에서 중복값을 찾는 기준이 되는 열번호(self.search_col_num)를 가져와 행단위로 출력된 (i)를 비교하여 없을 경우만 빈 리스트에 추가해줍니다.(new_list.append(i))
- (8행) 중복된 데이터를 제거한 내용을 엑셀에 쓰기 위해 새로운 디비의 내용을 지워주고(Clear())
- (9행) 중복 되지 않은 데이터를 담은 리스트를 새로운 DB(new)가 있던 위치에 값으로 넣어줍니다.
- Range 함수의 value 넣기 위해서는 리스트의 크기와 정확히 일치해야 값을 입력할 수 있기 때문에 시작할 위치를 new 값을 유동적으로 변할 값을 Cells를 이용해 상대적인 위치를 지정합니다
- Cells() 함수의 경우 행번호,열번호를 입력해야 하기 때문에, 리스트(new_llist)의 행 크기- 1, 영 크기를 len() 함수를 이용하여 유동적인 리스트 크기를 찾아줍니다.

- (1~4행)이제 작성한 클래스 함수를 이용하여 파라미터를 넣고 실행하면, 파라미터에 맞춰 새로운 DB가 중복이 제거된 값만 새로고침 되는 모습을 보실 수 있습니다.
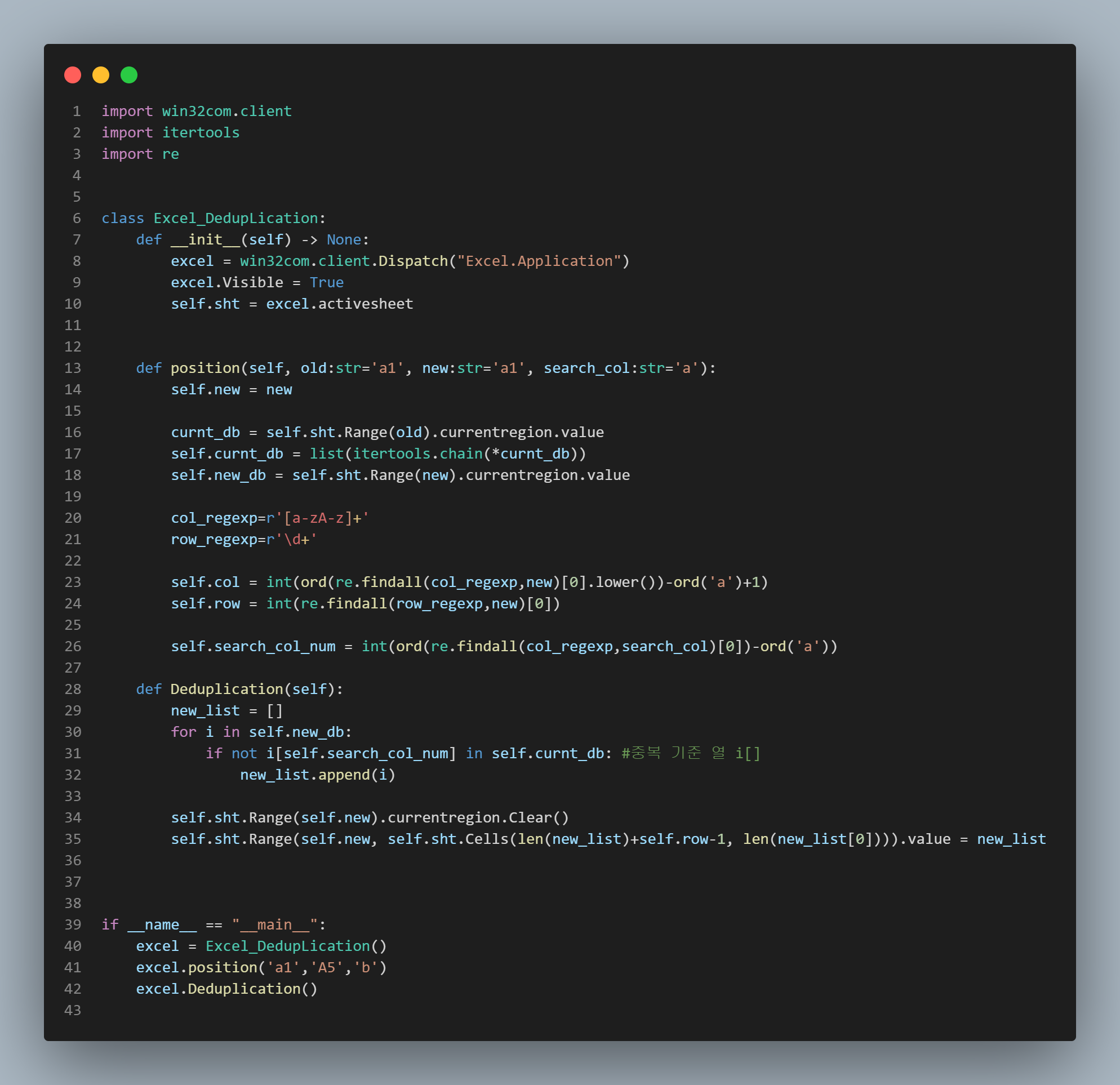
아래는 참고용 완성 코드입니다.
반응형
'Programing > Python' 카테고리의 다른 글
| [Python-Selenium-Chrome-RPA] 웹 사이트 자동 로그인(2) - 쿠키를 이용한 로그인 (0) | 2023.02.06 |
|---|---|
| [Python-Mail-RPA] Gmail, 메일 보내기 (0) | 2023.01.20 |
| [Python-Selenium -Chrome-RPA] 웹 사이트 자동 로그인(1) - 쿠키 얻기 (1) | 2023.01.16 |


